Geometría hiperbólica,
tocándola con las manos
Arrastra puntos, mueve sliders y mira cómo responde el espacio curvo. Cada herramienta calcula la geometría real (la misma del paper), no una caricatura: lo que ves medido es lo que ocurre en la bola de Poincaré.
La historia completa, de un vistazo
Pregunta: ¿cuándo y cómo ayuda la geometría hiperbólica en few-shot learning? Mismo encoder en todo; solo cambia la geometría de la cabeza. Predicción: el hiperbólico debería ganar solo si se dan dos condiciones a la vez — jerarquía y dimensión baja.
Bloque A — ¿gana en accuracy? (concluyente)
| Experimento | Resultado |
|---|---|
| CIFAR-FS (dim 256) | euclídea 50.8/71.9 vs hiperb. 48.5/57.3 → euclídea gana |
| FC100 / tieredImageNet | euclídea gana; la curvatura aprendible →0 (≈euclídeo) |
| Barrido de dimensión | dim 2-3: gana el hiperbólico; cruce en dim 4-8 |
| WordNet (jerarquía pura) | hiperb. dim 5 ≈ euclídeo dim 50-200 (10-40× menos dim) |
En accuracy, el hiperbólico gana solo con dimensión baja Y jerarquía explotable; en few-shot plano de dim alta (lo habitual), gana el euclídeo.
Bloque B — ¿induce estructura jerárquica? (exploratorio)
La estructura emerge solo a medias; un loss jerárquico la fuerza (pureza 43→79%) a costa de ~4 pts de accuracy. La fuente importa: un LLM da gratis una taxonomía casi humana (ARI 0.85); el clustering de features da similitud visual (0.26). Los conos de implicación son la pieza que induce la anidación radial (padres al centro), con trade-offs.
Tesis: el espacio hiperbólico no es un mejor clasificador few-shot; es un mejor espacio de representación para datos jerárquicos en dimensión baja. Hacen falta las dos condiciones: si falta cualquiera, el euclídeo gana o empata.
Hay tres geometrías, y la curvatura las distingue
En la esfera (curvatura \(K>0\)) la suma de los ángulos de un triángulo pasa de \(180°\); en el plano (\(K=0\)) es exactamente \(180°\); en el plano hiperbólico (\(K<0\)) es menos. No podemos dibujar \(\mathbb{H}^2\) sin distorsión en una hoja plana, así que usamos mapas — igual que con la Tierra. El más famoso es el disco de Poincaré: todo cabe dentro de un círculo, y un factor de escala corrige las distancias.
Las herramientas de abajo trabajan todas en el disco de Poincaré. La regla mental: lo que el dibujo encoge cerca del borde, la geometría lo estira.
La métrica: una escala que crece hacia el borde
Medir es sumar pasitos (Pitágoras: \(ds^2=dx^2+dy^2\)). En el disco, cada pasito del mapa se multiplica por un factor de escala local \(\lambda_x=\dfrac{2}{1-\lVert x\rVert^2}\): vale 2 en el centro y se dispara cerca del borde. Por eso el borde está a distancia infinita aunque en el dibujo parezca pegado.
Arrastra el punto
El color es \(\log_{10}\lambda\). Fíjate: mover el punto un poco cerca del borde dispara la distancia real al origen.
El camino más corto se curva — y eso es "ser recta"
Como los pasos son más baratos cerca del centro, el camino más corto (la geodésica) se comba hacia dentro. "Recta" no significa 90°: significa el camino que gasta exactamente la distancia (el test del andarín). Arrastra A y B y compara el segmento recto del dibujo con la geodésica real.
Arrastra A y B
El segmento azul parece recto pero malgasta longitud; la geodésica roja es la verdadera línea recta del espacio hiperbólico.
Por un punto pasan infinitas paralelas
Niega el quinto postulado de Euclides: por \(P\) pasan infinitas geodésicas que no cortan a \(L\). Y son de dos tipos: paralelas límite (se acercan a \(L\) sin tocarla) y ultraparalelas (guardan una distancia mínima positiva). Arrastra \(P\).
Arrastra P
Todas evitan a \(L\) (la azul); que se corten entre sí en \(P\) no es un fallo: "paralela" es una relación con \(L\).
El espacio crece exponencialmente
La circunferencia de radio real \(\rho\) mide \(2\pi\sinh\rho\approx \pi e^{\rho}\): crece exponencialmente, frente al \(2\pi\rho\) del plano. Por eso un árbol —cuyos nodos crecen como \(b^\ell\)— cabe sin amontonarse en el plano hiperbólico, y no en el euclídeo. Mueve el radio:
El mapa exponencial: meter vectores en la bola (y la saturación)
Una red neuronal produce vectores euclídeos \(v\) sin límite de norma. El mapa exponencial \(\exp_0^c(v)=\tanh(\sqrt c\,\lVert v\rVert)\,\frac{v}{\sqrt c\,\lVert v\rVert}\) los mete en la bola. Sube la norma: verás que con \(c=1\) todos se aplastan contra el borde (saturación / shell collapse) — el problema real al entrenar. Activa el clipping o baja la curvatura \(c\) y mira cómo se recupera.
Controles
Clipping = techo (no normalización): los vectores cortos pasan intactos, solo se recorta el exceso.
El mismo espacio, tres mapas
Poincaré, Klein y el semiplano superior son el mismo espacio hiperbólico dibujado distinto. Arrastra los vértices del triángulo en el disco de Poincaré y mira cómo se ve simultáneamente en los otros dos: Klein endereza las geodésicas (a cambio de mentir en los ángulos), el semiplano manda el borde al eje real.
Poincaré (arrastra aquí)
Klein (rectas)
Semiplano superior
Promediar puntos: Einstein vs Fréchet
El punto medio de Einstein es una fórmula cerrada y rápida (pasa por Klein); la media de Fréchet es el verdadero minimizador de \(\sum_i d^2\), pero hay que iterar. Coinciden con 2 puntos; con 3+ no, y Einstein queda sesgado hacia los puntos del borde — exactamente el efecto que penaliza al modelo 5-shot del experimento.
Arrastra los puntos
Las líneas verdes son las geodésicas del Fréchet a cada punto. Mete un punto al borde y mira cómo Einstein se va hacia él.
¿Para qué sirve todo esto? Few-shot learning en CIFAR-FS
Pusimos la teoría a prueba en CIFAR-FS, un benchmark real de few-shot (imágenes de CIFAR-100). Misma red prototípica con encoder Conv4 idéntico, solo cambia la geometría de la cabeza: la euclídea usa media + distancia euclídea; la hiperbólica proyecta al disco con exp₀, promedia con el punto medio de Einstein y clasifica por distancia de Poincaré.
El primer choque con la realidad: la hiperbólica "tal cual" (c=1) se hunde, porque las normas del encoder (~17–24) saturan el tanh y todos los embeddings colapsan al borde — exactamente la saturación que viste en la herramienta del mapa exponencial. Las defensas de la lección (feature clipping, curvatura pequeña, curvatura aprendible) recuperan ~8 puntos, pero la euclídea gana igualmente: CIFAR-FS no es fuertemente jerárquico y la dimensión (256) es alta.
| Cabeza (CIFAR-FS, 5-way) | 1-shot | 5-shot |
|---|---|---|
| Euclídea | 50.8% | 71.9% |
| Hiperbólica vanilla (c=1) | 41.7% | 50.0% |
| Hiperbólica + clip + curvatura aprendible | 48.5% | 57.3% |
Repetimos en FC100 (CIFAR-100 partido por superclase): mismo patrón, la euclídea gana (33.1/47.7 vs 30.8/37.5). Y a gran escala en tieredImageNet (351/160 clases, super-categorías WordNet): otra vez la euclídea (46.1/67.1 vs 43.5/53.6 la hiperbólica afinada) — y la curvatura aprendible converge a c≈0.0001, casi el límite euclídeo: sin jerarquía dentro del episodio, el propio modelo apaga la hiperbolicidad. Tres benchmarks reales, misma conclusión: partir por superclase no basta; faltaba la dimensión baja.
La prueba decisiva: bajar la dimensión
Añadimos un cuello de botella (proyección a d dimensiones tras el encoder) y barrimos d. Aparece el cruce que predice la teoría: en dimensión 2–3 el hiperbólico ADELANTA al euclídeo sobre imágenes reales; el cruce está en d ≈ 4–8.
| emb_dim (CIFAR-FS 5-way) | Euclídea 1s / 5s | Hiperbólica 1s / 5s |
|---|---|---|
| 2 | 35.7 / 45.8 | 41.0 / 49.5 |
| 3 | 39.0 / 51.0 | 43.2 / 52.0 |
| 8 | 47.2 / 63.0 | 46.3 / 56.9 |
| 64 | 50.4 / 69.6 | 47.4 / 55.8 |
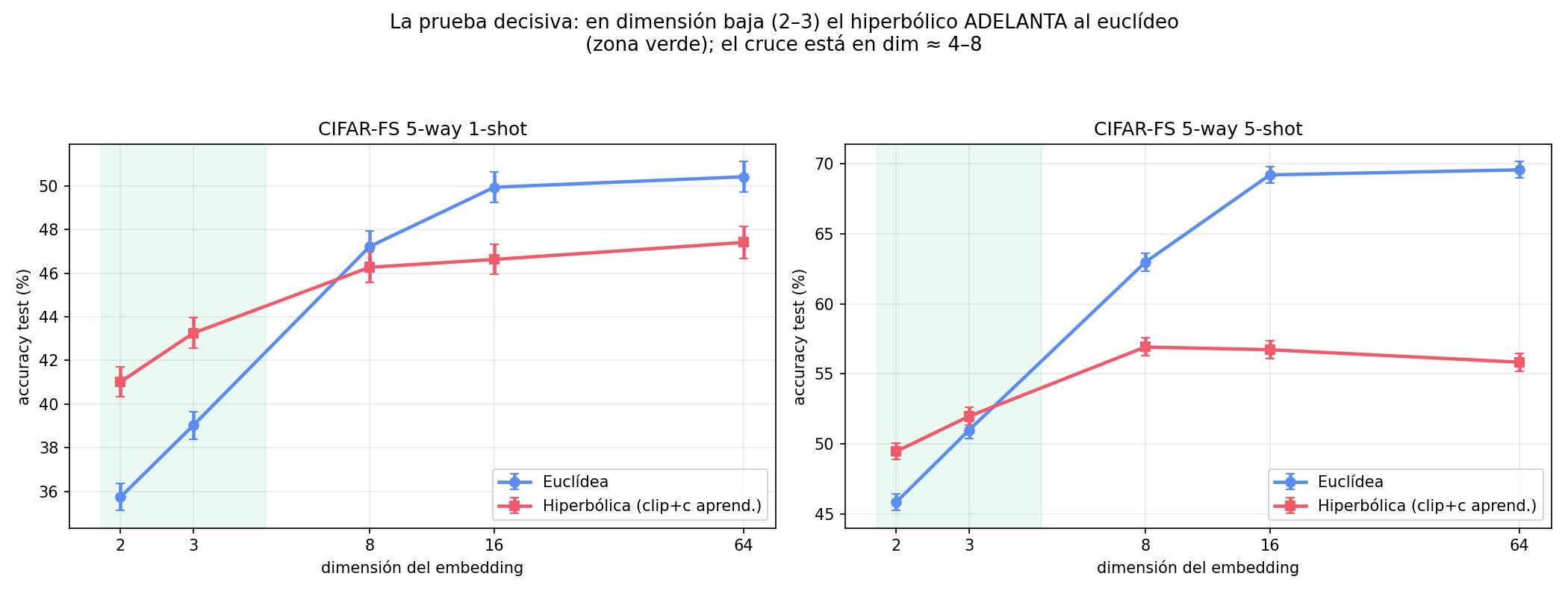
A dimensión alta el euclídeo va sobrado de sitio y gana; la ventaja hiperbólica vive en la dimensión baja.
El caso límite: jerarquía profunda real (WordNet)
Para verlo en su forma extrema, embebemos el subárbol de mamíferos de WordNet (1170 nodos, profundidad 9 — el benchmark de Nickel & Kiela 2017). Aquí la jerarquía es la tarea: medimos cuán bien se reconstruye el árbol (MAP) según la dimensión.
| dim | Euclídeo (MAP) | Hiperbólico (MAP) |
|---|---|---|
| 5 | 0.23 | 0.91 |
| 10 | 0.39 | 0.93 |
| 50–200 | 0.92 | 0.90–0.92 |
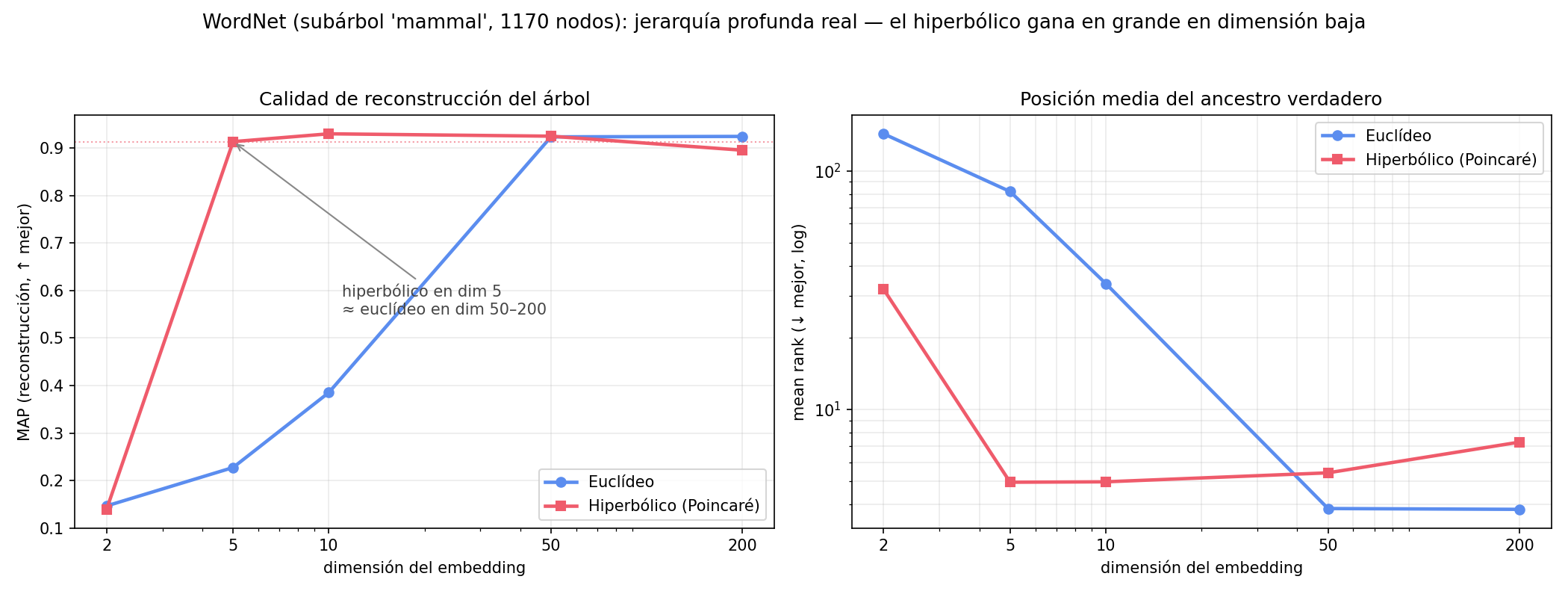
El titular: el hiperbólico en 5 dimensiones iguala al euclídeo en 50–200 — una reducción de 10–40×. Conclusión de todo el proyecto: el espacio hiperbólico es un sesgo inductivo para representaciones compactas de datos jerárquicos, no una mejora universal. La historia completa —saturación, las tres defensas, FC100, el cruce de dimensión y WordNet— en EXPERIMENTS.md.
¿De dónde sacamos la jerarquía? Tres formas, dibujadas
Si la jerarquía no sobrevive al episodio, hay que dársela. La construimos sobre las 100 clases de CIFAR-100 de tres maneras y las comparamos con las 20 superclases humanas (Adjusted Rand Index). Primero, cómo se distribuyen las clases en el disco aprendido (sin guía jerárquica): emerge estructura, pero parcial.
1 · Clustering de los prototipos (similitud visual)
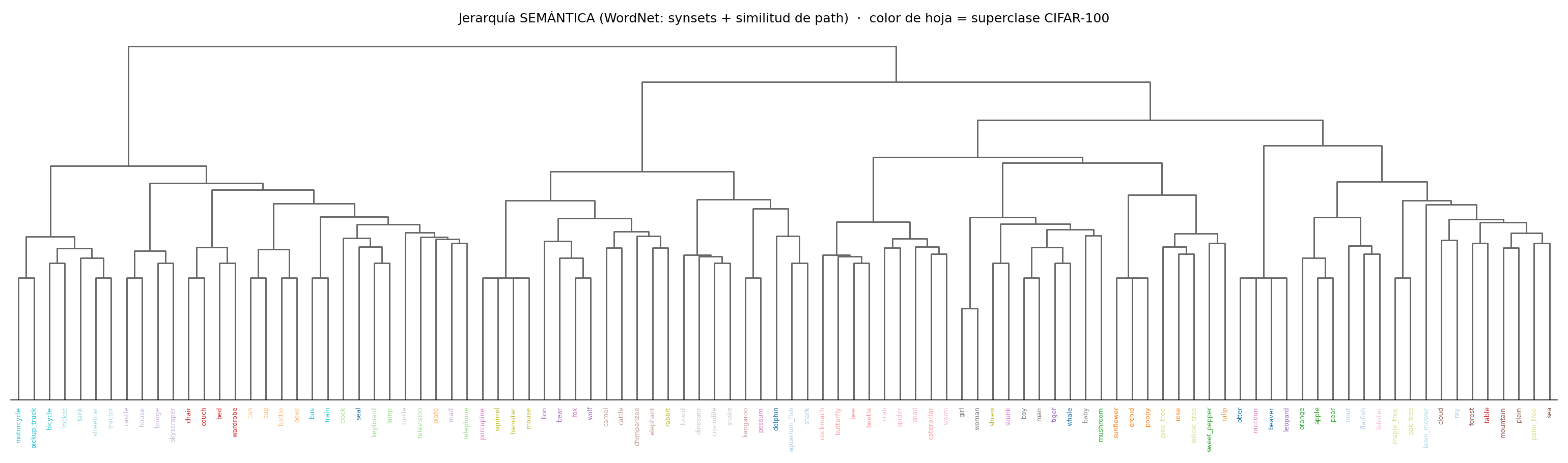
2 · WordNet (semántica léxica)
3 · LLM (Claude agrupa los nombres)
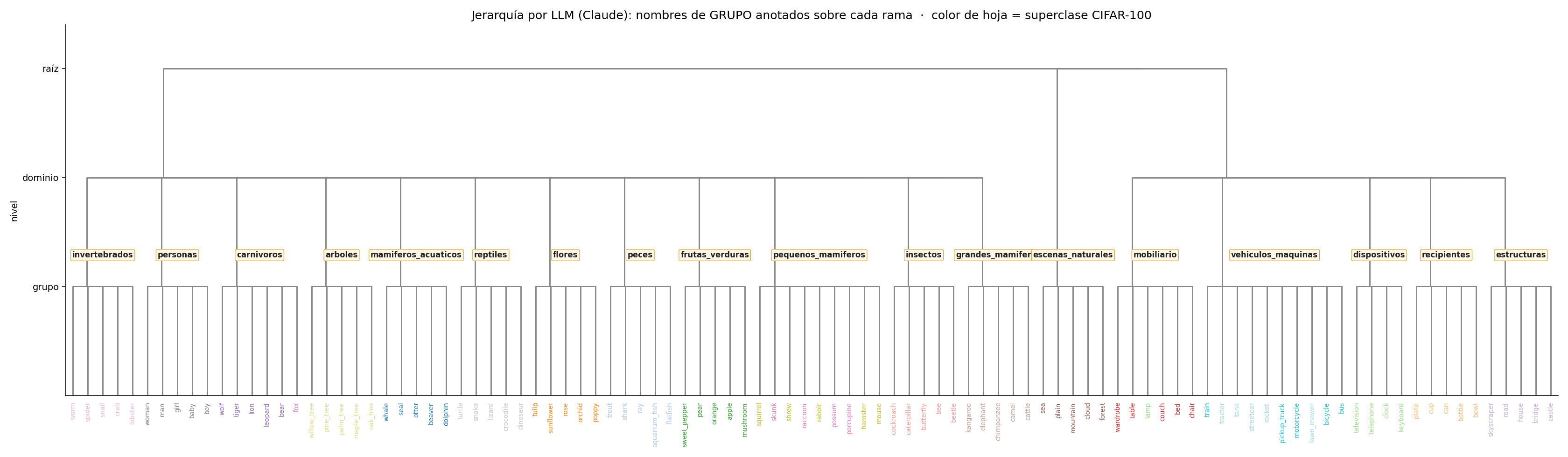
Comparación (ARI): el LLM ≈ jerarquía humana (0.85), WordNet 0.41 (semántica con ruido léxico), y el clustering solo 0.26 — captura similitud visual, no taxonomía.
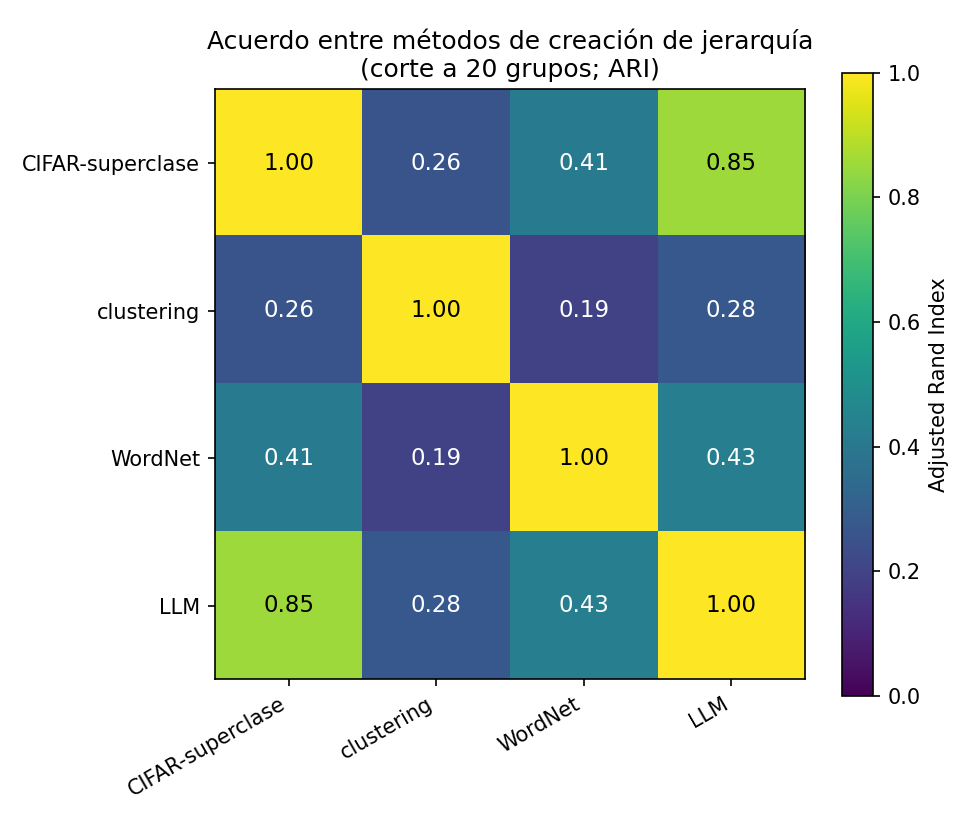
Conclusión: si quieres una jerarquía semántica para guiar al modelo, no la saques de las features (dan grupos visuales) — un LLM da, gratis y solo con los nombres, una taxonomía casi idéntica a la humana.
Imponer la jerarquía con una pérdida
El paso final: añadir un loss jerárquico al entrenamiento. Diseñé una pérdida auxiliar simple (inspirada en prototipos jerárquicos / conos de implicación): además del objetivo few-shot, mantengo prototipos de grupo aprendibles en la bola y empujo cada imagen hacia el prototipo de su grupo por distancia de Poincaré:
\( \mathcal{L} = \underbrace{\mathrm{CE}\big(\mathrm{softmax}_k(-d_c(z_q, p_k)),\, y_q\big)}_{\text{few-shot}} + \lambda\,\underbrace{\mathrm{CE}\big(\mathrm{softmax}_g(-d_c(z_i, G_g)),\, g(i)\big)}_{\text{grupo (jerarquía)}} \)
con prototipos de episodio \(p_k\) (punto medio de Einstein), prototipos de grupo aprendibles \(G_g\), y el grupo \(g(i)\) tomado de cada fuente. Resultado, comparando las 4 fuentes contra el baseline:
Cómo medimos la organización (sobre los prototipos de las 100 clases y su matriz de distancias de Poincaré):
• ratio de organización = distancia media entre superclases distintas ÷ distancia media dentro de la misma superclase. Global: 1 = sin estructura; >1 = las hermanas están más cerca.
• pureza del vecino = % de clases cuyo vecino más cercano comparte superclase. Local y estricta; el azar es ≈4%.
Ejemplo con 4 clases (dolphin, whale = misma superclase; bicycle, rose): d(dolphin,whale)=0.47, y los otros 5 pares de media 2.58 → ratio = 5.5. Vecino más cercano: dolphin→whale ✓, whale→dolphin ✓, bicycle→(otra familia) ✗, rose→✗ → pureza = 2/4 = 50%.
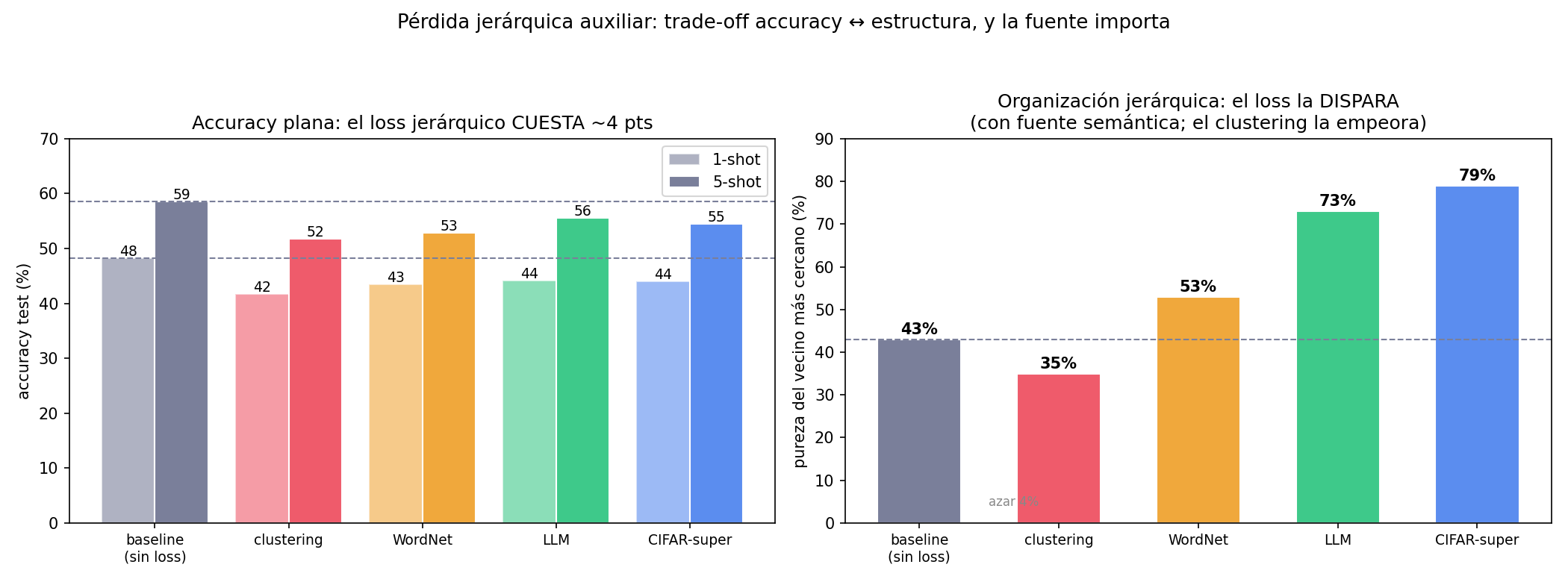
| Fuente del grupo | 1-shot / 5-shot | pureza vecino |
|---|---|---|
| baseline (sin loss) | 48.3 / 58.5 | 43% |
| clustering | 41.7 / 51.8 | 35% ↓ |
| WordNet | 43.4 / 52.9 | 53% |
| LLM | 44.2 / 55.6 | 73% |
| CIFAR-superclase | 44.1 / 54.5 | 79% |
Tres conclusiones: (1) el loss jerárquico organiza el espacio muchísimo (pureza 43→79%), (2) pero cuesta ~4 puntos de accuracy plana — es estructura a cambio de precisión, no una mejora gratis, (3) la fuente es decisiva: el clustering visual hace daño; el LLM iguala a la jerarquía humana. El código del loss está en src/exp_hier_loss.py.
¿Y tiene forma de árbol? (δ-Gromov + Ollivier-Ricci)
La pureza mide alineación con la taxonomía, pero no si el espacio es geométricamente tipo árbol. Dos métricas intrínsecas (sin etiquetas): δ-hiperbolicidad de Gromov (0 = árbol exacto, 1 = nada hiperbólico) y curvatura de Ollivier-Ricci (negativa = ramas tipo árbol; positiva = islas densas). Dibujamos cada modelo en el disco con su árbol de expansión mínima:
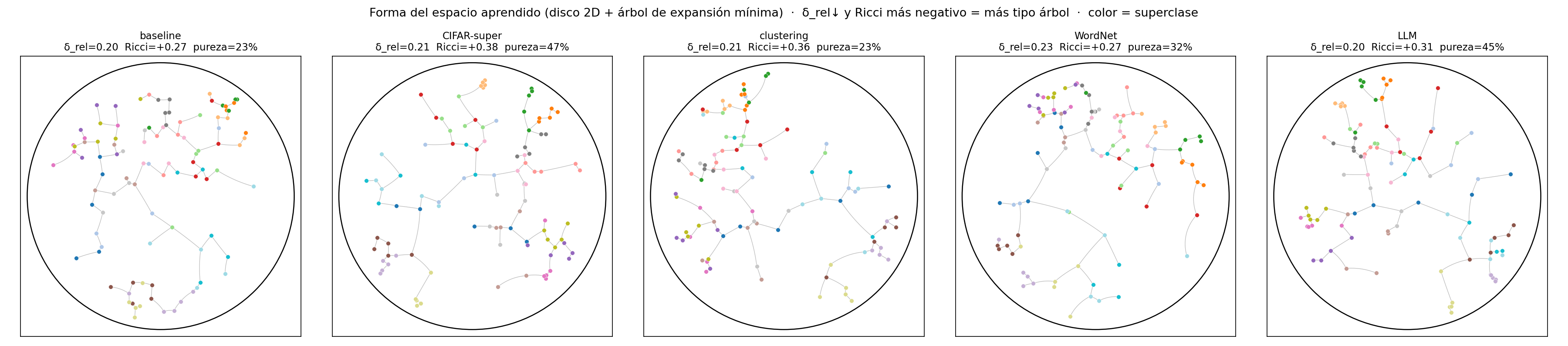
Hallazgo sorprendente: el loss jerárquico NO hace el espacio más tipo árbol. La δ-Gromov apenas se mueve (~0.20) y la Ollivier-Ricci es positiva y hasta sube con el loss (+0.27→+0.38): localmente el espacio se vuelve más denso, no más ramificado. O sea: alineación con la taxonomía ≠ forma de árbol — el loss crea islas compactas (sube la pureza) pero no la anidación radial de un árbol. Para eso haría falta un loss de contención / conos de implicación (grupo cerca del origen, clases hacia el borde). El MST siempre se dibuja como árbol por construcción; la forma real la dan δ y la curvatura.
Conos de implicación: forzar la anidación radial
El remedio: en vez de "pégate al prototipo de tu grupo", usar conos de implicación (Ganea 2018). Cada prototipo de grupo (padre) define un cono que se abre hacia el borde; cada clase (hijo) debe caer dentro del cono de su grupo. Por construcción, esto pone al padre cerca del origen (genérico) y al hijo afuera (específico): la anidación de un árbol.
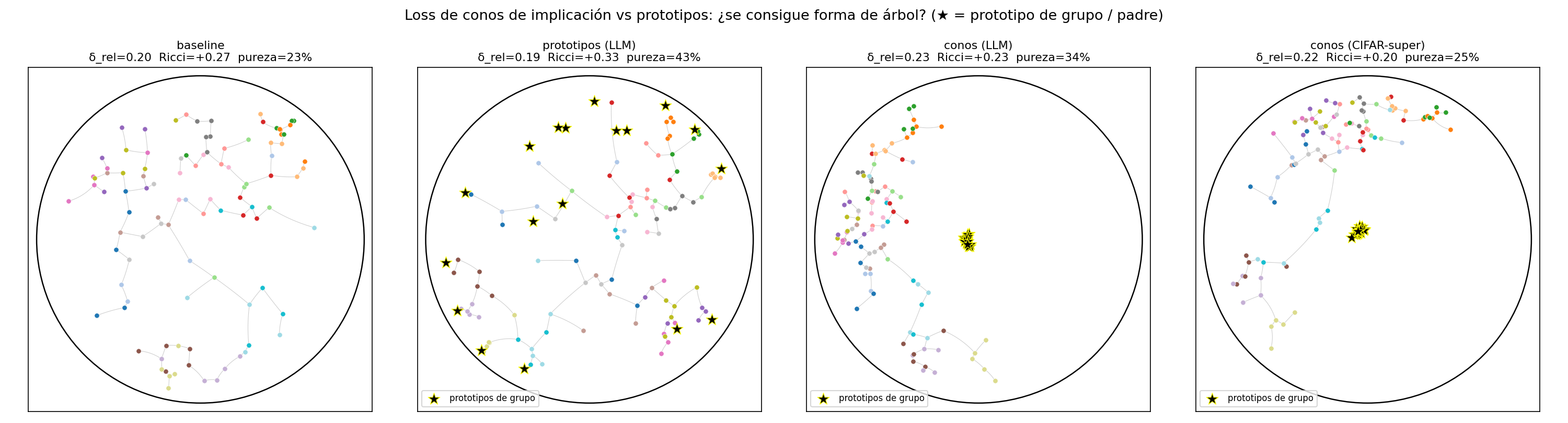
| Loss | Ollivier-Ricci | pureza | ‖grupo‖ (padres) |
|---|---|---|---|
| baseline | +0.27 | 23% | — |
| prototipos (LLM) | +0.33 | 43% | 0.77 (dispersos) |
| conos (LLM) | +0.23 | 34% | 0.07 (al centro) |
| conos (CIFAR-super) | +0.20 | 25% | 0.08 (al centro) |
Los conos SÍ consiguen la anidación radial que ningún otro loss lograba: los prototipos de grupo (★ en la figura) colapsan al centro (‖grupo‖ 0.77→0.07) y las clases van al borde — la firma de un árbol. La curvatura de Ollivier-Ricci se mueve hacia árbol (+0.27→+0.20), mientras los prototipos la empeoraban (+0.33). Pero con matices honestos: no llega a curvatura negativa, y los conos sacrifican pureza (43→34%) porque apiñar los grupos en el centro mezcla familias angularmente. La dirección queda demostrada —el cono es la pieza geométrica correcta— pero forma de árbol pura + alineación + accuracy a la vez sigue abierto (probablemente pide más dimensión y menos clip).
¿Y si hacemos la red más hiperbólica?
Hasta aquí solo la cabeza era hiperbólica. ¿Y si construimos capas hiperbólicas de verdad, o una CNN entera en la bola? Existen — y las probamos. Una capa hiperbólica hace lo mismo que una normal, pero envuelta entre log₀ y exp₀ (baja al tangente plano, hace el álgebra de siempre, vuelve a la bola); las sumas son de Möbius (⊕).
| Operación | Capa normal | Capa hiperbólica |
|---|---|---|
| lineal | Wx | exp₀(W·log₀(x)) |
| bias / sumar | +b | ⊕b (Möbius) |
| activación | σ(x) | exp₀(σ(log₀(x))) |
| pooling / media | media | punto medio de Einstein |
| logit | ‖·‖, ⟨·⟩ | distancia de Poincaré |
Existe a todos los niveles: capas densas (HNN, Ganea 2018), CNNs (Poincaré ResNet 2023, HCNN 2024) y transformers (atención hiperbólica 2019; Hypformer, KDD 2024). Aviso: una pila de capas solo lineales colapsa a euclídea — la curvatura real entra por el bias de Möbius, las activaciones en la bola y la distancia final.
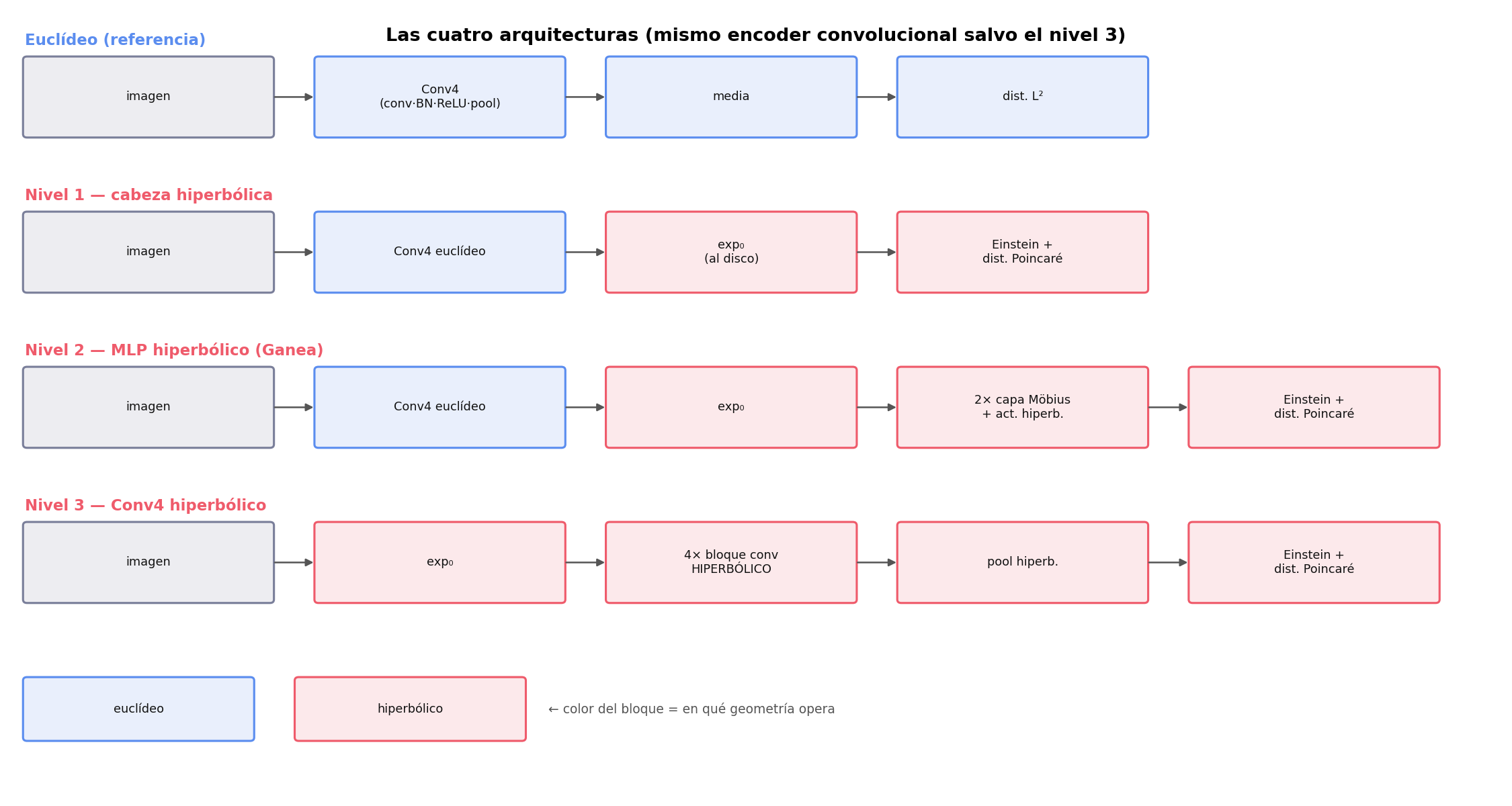
Resultado: más hiperbólico NO es mejor
| Modelo (CIFAR-FS 5-way) | 1-shot | 5-shot |
|---|---|---|
| euclídeo Conv4 | ~52 | ~73 |
| Nivel 1 — cabeza hiperbólica | 45.4 | 53.5 |
| Nivel 2 — MLP hiperbólico (Möbius) | 37.0 | 49.5 |
| Nivel 3 — Conv4 totalmente hiperbólico | 43.5 | 55.0 (6× más lento) |
| Transformer (ViT) euclídeo — FC100 | 32.1 | 43.4 |
| Transformer (ViT) hiperbólico — FC100 | 28.4 | 38.0 (5× más lento) |
Conclusión honesta: hacer la red más hiperbólica empeora (la cabeza profunda, la convolución Y el transformer hiperbólicos pierden vs euclídeo y cuestan 5-6× más). Las capas Möbius son difíciles de optimizar y con pocos datos no se rentabilizan. El cuello de botella no está en la arquitectura: el beneficio hiperbólico, donde lo hay, viene de la geometría del embedding en dimensión baja con jerarquía, no de "hiperbolizar" la red.
Encoder preentrenado: ¿y si el embedding ya es bueno?
El estado del arte en FC100 no entrena el ViT desde cero: usa transformers preentrenados (FewTURE 46/63, CPEA 47/65, BiKop 53/65 con ViT-S). Nuestro ViT de juguete (32/43) y hasta el Conv4 (33/48) no son representativos — el cuello de botella era la calidad del embedding, no la geometría. Pregunta limpia: con un foundation model real congelado como encoder, ¿la cabeza hiperbólica aporta? Usamos DINOv2 ViT-S/14 (auto-supervisado, 22M params) congelado, y comparamos la misma cabeza euclídea vs hiperbólica.

Las 12 configuraciones = ① encoder (congelado vs fine-tuned 2 bloques) × ② dimensión (384 / 16 / 3) × ③ geometría de la cabeza (euclídea vs hiperbólica). La cadena imagen→resize→DINOv2 es común a todas.
| Cabeza (DINOv2 congelado · FC100) | dim | 1-shot | 5-shot |
|---|---|---|---|
| euclídea (sin entrenar) | 384 | 72.1 | 86.2 |
| hiperbólica (sin entrenar) | 384 | 71.2 | 85.3 |
| euclídea | 16 | 47.4 | 63.1 |
| hiperbólica | 16 | 39.5 | 51.8 |
| euclídea | 3 | 34.7 | 42.5 |
| hiperbólica | 3 | 34.7 | 42.8 |
(1) El embedding preentrenado lo es todo. DINOv2 congelado, sin entrenar nada, da 72/86: aplasta a nuestro ViT y Conv4 desde cero y supera al SOTA few-shot citado (el secreto es el preentrenamiento). Matiz: DINOv2 vio un corpus enorme, así que esto es transfer, no few-shot "limpio" — pero confirma el punto. (2) Sobre un embedding euclídeo, la bola de Poincaré no aporta: la cabeza hiperbólica pierde a toda dimensión (solo empata en dim 3), al revés que el Conv4 desde cero (donde ganaba en dim 2-3). DINOv2 produce embeddings isótropos optimizados para separabilidad lineal, no jerárquicos. Refinamiento de la tesis: el hiperbólico necesita jerarquía EN la representación, no solo dimensión baja.
¿Y si dejamos que el ViT se adapte? (fine-tuning)
Descongelamos los últimos 2 bloques del ViT-S y los entrenamos con cada geometría, para ver si el transformer puede desarrollar la jerarquía que le falta:
| Cabeza (DINOv2 fine-tuned · FC100) | dim | 1-shot | 5-shot |
|---|---|---|---|
| euclídea | 384 | 50.6 | 61.4 |
| hiperbólica | 384 | 48.6 | 55.9 |
| euclídea | 16 | 47.5 | 60.6 |
| hiperbólica | 16 | 41.2 | 51.3 |
(i) El fine-tuning degrada (384: 72→51) — overfit sobre el split diminuto de FC100, deteriorando features que ya eran excelentes. (ii) Y lo decisivo: la cabeza hiperbólica sigue perdiendo aun dejando que el ViT se adapte (16: 41.2 vs 47.5). Reorganizar 2 bloques de un ViT preentrenado en euclídeo no hace emerger jerarquía. La ventaja hiperbólica exige una representación intrínsecamente jerárquica, no solo un encoder potente al que se le baje la dimensión.
La escalera de hiperbolización: ¿dónde se rompe?
Hasta ahora comparábamos "euclídeo" vs "hiperbólico" como bloques. Pero el modelo tiene varias piezas hiperbolizables por separado (la métrica final, el bias/activación de la cabeza, las convoluciones). Para aislar cuál aporta o estorba, construimos una escalera anidada: partir de un Conv4 totalmente euclídeo y sustituir una pieza por su versión hiperbólica en cada peldaño. CIFAR-FS 5-way, mismo presupuesto y semilla, a dim alta (64) y baja (3).

| Peldaño (+1 pieza hiperbólica) | dim 64 | dim 3 | ||
|---|---|---|---|---|
| 1-shot | 5-shot | 1-shot | 5-shot | |
| S0 euclídeo | 52.1 | 69.9 | 44.2 | 55.1 |
| S1 +dist. Poincaré | 38.6 | 55.1 | 37.3 | 52.9 |
| S2 +Möbius×1 | 34.5 | 54.7 | 36.4 | 54.4 |
| S3 +Möbius×2 | 36.9 | 54.5 | 36.4 | 47.4 |
| S4 +conv hip.×1 | 36.4 | 53.0 | 37.1 | 48.4 |
| S5 conv hip.×4 | 36.4 | 55.0 | 39.8 | 50.4 |
(1) El acantilado es la métrica, no las capas. Todo el deterioro ocurre en S1 (meter la distancia de Poincaré); apilar capas Möbius o convoluciones hiperbólicas encima ni arregla ni cambia gran cosa — curva plana tras S1. (2) El precio se desploma en dim baja: la caída S0→S1 en 5-shot pasa de −14.8 pts (dim 64) a −2.2 (dim 3), y en S2 a dim 3 iguala al euclídeo (54.4 ≈ 55.1). (3) Más capas Möbius perjudican con pocos datos (S3 dim 3: 54.4→47.4) y cuesta ×7 entrenar.
Matiz honesto: en el barrido dedicado el hiperbólico ganaba a dim 2-3; aquí solo iguala. La diferencia es el cuello de botella (aquí global-avg-pool→64, allí flatten 256, + menos episodios), que da un euclídeo más fuerte a dim 3. No contradice la tesis — la dim baja sigue siendo el único régimen competitivo del hiperbólico. Conclusión: el beneficio hiperbólico, donde lo hay, entra por la métrica final y solo cuando falta dimensión; hiperbolizar las capas internas solo añade coste.
Un peldaño más: el modelo de Lorentz
Toda la escalera usa la bola de Poincaré. Pero la literatura advierte: "las redes de Poincaré son consistentemente peores que el euclídeo, mientras que las de Lorentz (hiperboloide) superan a ambos" — el hiperboloide se optimiza mejor (sin singularidad en el borde). Era nuestra única laguna frente al SOTA, así que repetimos los peldaños de cabeza en Lorentz (mismo encoder, dim y presupuesto): exp en el hiperboloide, centroide de Lorentz como prototipo, distancia de Lorentz y capa lineal de Lorentz (Chen 2022).

| Cabeza | dim 64 | dim 3 | ||
|---|---|---|---|---|
| 1-shot | 5-shot | 1-shot | 5-shot | |
| euclídeo (S0) | 52.1 | 69.9 | 44.2 | 55.1 |
| Poincaré métrica (S1) | 38.6 | 55.1 | 37.3 | 52.9 |
| Lorentz métrica (L1) | 45.7 | 55.6 | 45.4 | 57.0 |
| Poincaré +1 capa | 34.5 | 54.7 | 36.4 | 54.4 |
| Lorentz +1 capa | 43.3 | 54.9 | 41.7 | 53.1 |
| Poincaré +2 capas | 36.9 | 54.5 | 36.4 | 47.4 |
| Lorentz +2 capas | 42.6 | 53.5 | 38.2 | 44.9 |
(1) Lorentz ≫ Poincaré, sobre todo en 1-shot (+7 a +9 pts a dim 64; +5 a +8 a dim 3) y más barato (~40s). (2) La métrica de Lorentz gana al euclídeo en dim baja: a dim 3, L1 da 45.4/57.0 vs 44.2/55.1 del euclídeo — el resultado positivo limpio que buscábamos, que resuelve la tensión con el barrido. Lo que no cambia: apilar capas sigue perjudicando también en Lorentz (a dim 3, L3 se desploma a 44.9). El modelo de Lorentz arregla cómo de bien se optimiza la métrica, no rescata las capas internas. Mejor configuración hiperbólica: Lorentz + solo la métrica + dimensión baja.
De la descripción a la causa: ¿es navegable el espacio?
Hasta aquí hemos descrito geometría. La pregunta más profunda (en la línea de la Platonic Representation Hypothesis) es si esa geometría es funcionalmente navegable: ¿el modelo usa la posición en el espacio o solo la exhibe? Hipótesis falsable sobre los dos ejes de la bola: el radio codifica la abstracción (raíz≈centro, hojas≈borde) y el ángulo codifica la categoría.
Qué movemos, cuál es la salida, y la fórmula
Qué movemos: un punto = el embedding de una imagen ya proyectado a la bola. Tiene dirección (x̂ = categoría) y radio (‖x‖ = especificidad). Lo deslizamos hacia el centro manteniendo la dirección — como la raíz está en el centro, acercarse = ir a lo más abstracto (husky → perro → animal). La salida: a qué clase/nivel clasifica el punto movido.
La geodésica: x(t) = exp₀(t·log₀(x)) = x̂·tanh(t·arctanh‖x‖). log₀ lleva el punto al tangente plano del centro, donde su longitud es la distancia hiperbólica real arctanh‖x‖ (que explota en el borde); t encoge esa distancia; exp₀ lo devuelve a la bola conservando la dirección. Ej.: ‖x‖=0.9 → distancia 1.47; con t=0.5 el nuevo radio es tanh(0.5·1.47)=0.63. t=1 no mueve nada, t=0 va al centro.
Test observacional: la premisa se sostiene
Sobre DINOv2 congelado (CIFAR-100) + proyección de Poincaré post-hoc, medimos el radio por nivel, con un control anti-trivial (superclase real vs agrupación aleatoria del mismo tamaño):

H1 (radio=abstracción) ✓: fina 0.408 > super real 0.291 > aleatoria 0.189 > raíz 0.000. Que la superclase real quede a mayor radio que la aleatoria descarta que sea un artefacto de promediar. H2 (ángulo=categoría) ✓: coherencia angular real 0.36 vs aleatoria ≈0.
La intervención: el espacio es navegable (pero no solo el hiperbólico)
Tiramos cada imagen hacia la raíz (t:1→0) y la clasificamos contra prototipos finos + de superclase. Control: el mismo movimiento hacia la media euclídea con distancia L².

Verlo en vivo con una imagen real (un lobo de CIFAR-100):

Al tirar la imagen del lobo hacia el centro, la predicción del modelo sube de “wolf” (clase fina) a “large carnivores” (superclase): recorre el árbol de forma ordenada. Eso es navegar el espacio.
(1) La representación es funcionalmente navegable: al mover la imagen hacia el centro, la clase fina se desploma pero la superclase correcta sube — el modelo "sabe que es un perro pero ya no cuál". La rama correcta se conserva en ~84%. El radio es un eje de abstracción operativo, no solo descriptivo. (2) Pero no es exclusivo del hiperbólico: el control euclídeo da casi la misma escalera. La curvatura modula la velocidad del ascenso, no la corrección. Otra vez, "two sides of the same coin".
Advertencia metodológica: la versión cross-modal (mover imagen, leer qué texto elige CLIP) queda confundida por el modality gap — texto e imagen ocupan conos distintos, los prompts finos y de superclase caen al mismo radio (0.767 vs 0.768) y la intervención degenera en colapso trivial. La cirugía geodésica solo es interpretable intra-modal.
Una capacidad: abstención jerárquica ("saber cuándo ser vago")
Si el radio mide especificidad, el modelo puede —sin entrenar— responder la clase fina cuando está seguro y echarse atrás a la superclase cuando no. ¿Qué señal decide? ¿El radio (geometría) o el margen de confianza estándar?

La capacidad funciona (manteniendo 70% de respuestas finas, la accuracy sube de 78.1 a 84.2%), pero el radio pierde contra el margen (80.7 vs 84.2, apenas sobre el azar). La geometría no da mejor señal de incertidumbre por-query — el radio codifica abstracción a nivel de clase, no confianza por-ejemplo.
El test decisivo: doble disociación radio ⟂ ángulo
¿Aporta la curvatura algo que el euclídeo no pueda? Lo zanjamos "apagando" un eje y midiendo qué tarea sobrevive: CATEGORÍA (clasificar superclase, necesita ángulo) vs NIVEL (¿específico o genérico?, necesita radio).

Disociación limpia: la categoría sobrevive con solo-ángulo y muere con solo-radio (5%=azar); el nivel al revés. Radio y ángulo son ejes independientes (abstracción y categoría). Pero es idéntica en hiperbólico y euclídeo → la curvatura es una reparametrización fiel, no estructura añadida. El veredicto, tras cinco frentes (DINOv2, escalera, Lorentz, navegabilidad, abstención): la geometría hiperbólica casi nunca es el ingrediente activo; el único positivo genuino es Lorentz + métrica + dim baja, y por poco.
El juego coarse→fine: ¿puede el grueso corregir al fino?
Idea: usar la superclase para corregir la clase fina (si coinciden, aceptar la fina; si discrepan, rebuscar la fina dentro del grupo del coarse). Tres versiones sobre DINOv2 congelado:
- Redirect duro: empeora (78.1→69.6) — los errores del coarse se propagan.
- Redirect con confianza (umbral en validación): converge a "no redirigir" ≈ plana.
La razón: el coarse sale del mismo embedding que la fina → es información redundante. La prueba decisiva — un coarse independiente (de CLIP):

Funciona con un coarse independiente: el coarse de CLIP (otro modelo, menos preciso: 78.7%) mejora la fina de DINOv2 (78.25→79.27, +1.0), mientras que el coarse del propio DINOv2 (más preciso: 81.8%) no aporta nada (+0.04). No cuenta la precisión del coarse, sino su independencia — es un ensemble jerárquico. Encaja con la Platonic Representation Hypothesis: modelos que convergen en representación aún conservan errores complementarios. El techo lo marca el oráculo (86.2%).
Explotar la jerarquía: "mejores errores"
Si para accuracy la jerarquía no es la palanca, su valor real es la estructura de los errores: cuando el modelo falla, ¿falla cerca en el árbol (lobo→zorro) o lejos (lobo→silla)? Medimos la severidad con la distancia en el árbol (0 fina, 1 hermano, 2 superclase distinta).

(1) La jerarquía estructura fuertemente los errores: 42-49% se quedan dentro de la superclase correcta vs 4% por azar (~10×) — los fallos ya son "leves" por defecto. (2) El hiperbólico no hace mejores errores que el euclídeo (treedist 0.344 vs 0.307): otra vez agnóstico a la geometría. (3) El coarse independiente (CLIP) sí reduce la severidad (41.8→48.6% dentro de superclase). La palanca es combinar modelos independientes a través de la jerarquía, no la curvatura.
Consenso multinivel: granularidad adaptativa
Dos modelos independientes (DINOv2 y CLIP) suben el árbol hasta donde coinciden y responden a ese nivel. El nivel de acuerdo = granularidad y confianza adaptativas.

El acuerdo entre modelos independientes es una señal de fiabilidad fortísima: donde coinciden en la clase fina (76.5%), aciertan el 92% (vs 80% de cada uno por separado); donde solo coinciden en superclase (8.5%), la respuesta gruesa acierta el 91%; y el 14.9% de desacuerdo es el tail difícil (accuracy individual ~40%) que se aísla y se marca. La jerarquía convierte el (des)acuerdo entre modelos convergentes en granularidad calibrada — la materialización práctica de la Platonic Representation Hypothesis.
El comité: la diversidad predice la ganancia
Si la palanca es la independencia, debería escalar con el nº de modelos diversos. Comité de 5 modelos de paradigmas distintos (DINOv2 SSL, CLIP contrastivo, ResNet-50 / ViT / ConvNeXt supervisados): exigimos que todos coincidan, subiendo el árbol al nivel de acuerdo.

| Comité (todos de acuerdo) | cob. fino | prec. fino | cob. super | prec. super |
|---|---|---|---|---|
| 2 modelos | 76.5% | 92.1% | 8.7% | 91.5% |
| 3 modelos | 54.6% | 94.0% | 13.8% | 96.4% |
| 4 modelos | 49.4% | 95.4% | 14.5% | 97.2% |
| 5 modelos | 45.8% | 96.0% | 15.1% | 98.1% |
Con los 5 modelos de acuerdo: 96% de precisión a nivel fino (45.8% del test) y 98% a nivel superclase (15.1%) → ~61% del test con respuesta de altísima fiabilidad a la granularidad que el comité puede garantizar; el resto se marca. Matiz honesto: el acuerdo de dos modelos supera al mejor de los dos por +12 pts de media (robusto), pero la hipótesis fuerte "más diversidad → más ganancia" no se sostiene con estos datos (al controlar por accuracy, ρ parcial ≈ 0.22 con n=10; el +0.38 inicial estaba confundido). Aun así, el cierre del arco: la jerarquía no es valiosa por la geometría hiperbólica, sino como andamiaje para combinar modelos que convergen en representación pero conservan errores complementarios — un puente entre la Platonic Representation Hypothesis y un sistema práctico de predicción fiable con granularidad adaptativa.
¿Y en hiperbólico? El consenso/comité usa la métrica natural de cada modelo (coseno). Para cerrar la consistencia, repetimos el comité con la proyección de Poincaré por modelo:

Geometría-agnóstico también aquí: las curvas euclídea (sólida) e hiperbólica (discontinua) se solapan (a k=5, precisión fina 96.0% euc vs 96.2% hip). La ganancia del consenso no viene de la curvatura, sino de la complementariedad entre modelos — coherente con los siete frentes anteriores.
Línea 🅐 — el radio no, pero la distancia sí: detección OOD
Una línea muy activa (grupo de Mettes, Hyperbolic Safety-Aware VLMs, CVPR 2025) sostiene que el radio hiperbólico codifica la (in)certidumbre y sirve para detectar contenido fuera de distribución (OOD) o inseguro. Lo probamos sobre DINOv2 congelado, con OOD near (20 clases CIFAR ocultas) y far (SVHN).

| Señal (AUROC OOD, 3 semillas) | near-OOD | far-OOD (SVHN) | ||
|---|---|---|---|---|
| euc | hip | euc | hip | |
| radio | 0.72 | 0.51 | 0.95 | 0.50 |
| max-logit (sin temp.) | 0.71 | 0.80 | 0.946 | 0.975 |
| energía | 0.71 | 0.62 | 0.946 | 0.966 |
| MSP | 0.80 | 0.81 | 0.84 | 0.97 |
(1) El radio NO es el eje de incertidumbre (en contra del relato habitual): el feature clipping que el hiperbólico necesita aplana los radios → azar (0.50) para OOD; la norma euclídea sí detecta. (2) Pero la DISTANCIA geodésica al prototipo SÍ detecta mejor en hiperbólico — robusto sobre 3 semillas (barras no solapan), sin temperatura (max-logit): +8.7 pts en near-OOD (0.80 vs 0.71), +2.9 en far-OOD (0.975 vs 0.946). Mecanismo: en la bola las distancias crecen exponencialmente hacia el borde, así que lo que está fuera del manifold queda exponencialmente lejos de todos los prototipos y se separa más nítido. Aquí la curvatura SÍ aporta — el valor del hiperbólico para incertidumbre no está en el radio (como se dice), sino en cómo su métrica amplifica la lejanía de lo OOD. Punto de partida de esta línea.
Generalidad: 5 backbones × 4 OOD — y la dicotomía del radio
Extendido a 5 backbones (DINOv2, CLIP, ResNet-50, ViT-sup, ConvNeXt) × 4 OOD (clases ocultas, SVHN, FashionMNIST, DTD) × 3 semillas. Cada punto = (backbone × OOD); sobre la diagonal = gana hiperbólico:

La distancia generaliza: max-logit hiperbólico gana en 15/20 celdas (Δ +0.067), y al mejor euclídeo en 14/20. El radio NO, y depende del backbone: en transformers el radio hiperbólico es inútil (0/12 — el clipping satura los radios), pero en CNNs es bueno (8/8 — no saturan). La fragilidad del radio depende de si el backbone satura el clipping — y CLIP/ViT, los más usados en la línea de seguridad hiperbólica, son justo los que lo saturan. (Fallo notable y reportado: CLIP+SVHN, donde el max-logit hiperbólico colapsa a 0.53.)

Mecanismo medido: DINOv2 y ViT saturan el clipping al 100% → radio literalmente constante (std=0.000) → AUROC 0.50; los CNN saturan menos (61-71%) y su radio conserva información (AUROC 0.82-0.85). Relación monótona: más saturación → radio más plano → radio inútil. El clipping (requisito de estabilidad del hiperbólico) es el responsable directo de que el radio no sirva en CLIP/ViT.
Generalidad a un segundo ID: Food-101
Repetimos el protocolo con un ID totalmente distinto (Food-101, 101 clases naturales), reutilizando los OOD:

Lo que generaliza (robusto): la dicotomía del radio se replica (transformers 0/12, Δ −0.22) — el debunk del radio no era un artefacto de CIFAR. Lo condicional: la ventaja del max-logit hiperbólico es nítida en near-OOD (lo difícil: DINOv2 +0.16, ViT +0.17, 4/5 backbones), pero en far-OOD de Food el euclídeo ya satura (~1.0) y no deja margen; CLIP vuelve a ser el punto flojo. Conclusión honesta: el debunk del radio es el resultado robusto (2 ID × 5 backbones × mecanismo); la ventaja de la distancia es real pero condicional.
El mecanismo: basta con que la métrica sea curva

Cualquier c>0 da el salto sobre el euclídeo (near 0.71→0.81, far 0.95→0.97 ya en c=0.1); la magnitud de c apenas importa (compromiso: far prefiere c alto, near c bajo). No es la magnitud de la curvatura, sino tener métrica curva (geodésica) lo que separa lo OOD.
Posicionamiento y relación con la seguridad hiperbólica
Competitivo y complementario: frente a Mahalanobis/KNN (sobre features crudas), el max-logit hiperbólico (training-free, un forward) es el mejor en 9/20 celdas y empata con Mahalanobis de media — pero arrasa en SVHN (DINOv2 0.975 vs Maha 0.670) donde los métodos de densidad flaquean, mientras Maha/KNN ganan en texturas. vs Poppi/Mettes (CVPR 2025): ellos entrenan CLIP en hiperbólico para seguridad apoyándose en el radio; nosotros, training-free, mostramos que ese radio es frágil justo para CLIP/transformers (el clipping lo mata) e identificamos la distancia geodésica como la señal robusta. Mensaje: para detectar lo anómalo en hiperbólico, no mires el radio — mira la distancia.
Capítulo nuevo — ¿cómo llevar un modelo euclídeo al espacio hiperbólico sin romper la geometría?
Toda nuestra investigación converge en un callejón sin salida geométrico que ahora podemos enunciar con precisión y que abre una pregunta nueva. Cuando cogemos un modelo preentrenado en espacio euclídeo (DINOv2, CLIP…) y proyectamos sus features a la bola de Poincaré con el mapa exponencial, la geometría se rompe en tres pasos que hemos medido:
- El shell collapse no lo causa el entrenamiento ni el clipping: ya en la inicialización (época 0, sin entrenar nada, sin clipping) los embeddings nacen a radio ≈0.996, pegados al borde, porque la
tanhdel mapa exponencial se satura para la escala normal de las features. Y el radio no se mueve en 60 épocas: solo cambian los ángulos. - En esa cáscara el gradiente se desvanece (vale ~10⁻⁴ del central), así que el radio queda congelado y la dimensión radial —donde viviría la jerarquía— es inutilizable.
- La prueba decisiva: clasificar los mismos embeddings con distancia de Poincaré o euclídea da lo mismo (81.2 vs 81.1), porque en una cáscara de radio fijo la distancia hiperbólica se reduce a la angular, que es la información que ya usa el euclídeo.

El compromiso fundamental: cerca del borde la curvatura es genuina pero el radio está congelado y la métrica colapsa a angular; en el interior el radio es usable pero la métrica es casi plana. En ningún régimen tienes a la vez radio usable y curvatura genuina — por eso un modelo euclídeo proyectado al hiperbólico se comporta como euclídeo.
El problema, interactivo
Mueve la escala α. Con α pequeña los puntos viven en el interior con radios variados (el radio es usable); con α grande la tanh los satura y colapsan a una cáscara en el borde. Observa los dos medidores: nunca consigues a la vez que el radio esté variado y que las dos métricas estén en desacuerdo — ese es el callejón.
La pregunta abierta de este capítulo: ¿cómo aprovechamos los modelos euclídeos y los pasamos al hiperbólico sin que la geometría colapse? La literatura tiene piezas parciales (clipping, modelo de Lorentz, curvatura aprendible, conos de implicación) pero ninguna lo resuelve limpiamente. Nuestro diagnóstico sugiere que la solución tendría que (i) evitar la saturación de la tanh, (ii) supervisar explícitamente el radio para que codifique jerarquía —porque la clasificación sola nunca lo usa— y (iii) operar en curvatura genuina sin caer en la cáscara. Empezamos el análisis aquí.
Verificación con el SOTA: el "fracaso" era de implementación, no de la geometría
El callejón es real para un modelo proyectado, pero ¿y un modelo entrenado de cero en hiperbólico? Lo pusimos a prueba en serio. Primero montamos una red totalmente de Lorentz desde cero y, aun portándole la normalización interna de Chen (reescala la parte espacial a una norma acotada y aprendible sigmoid(x₀)·es — justo el control de escala que el diagnóstico pedía) y una inicialización diminuta, se quedaba 18 puntos por debajo de la euclídea (55.5% vs 73.5% en CIFAR-10). Pero eso no condena a la geometría: corrimos el código oficial de HCNN (Bdeir 2024), que sí trae la batch-norm riemanniana completa, los bloques residuales de Lorentz y el clasificador MLR, sobre nuestra propia GPU.
| ResNet-18 · CIFAR-100 · 50 épocas | Test Acc@1 |
|---|---|
| Euclídea (E-ResNet18) | 74.20% |
| Lorentz (HCNN completo) | 74.76% |
| Δ (Lorentz − euclídeo) | +0.56 |
Nuestra red de Lorentz desde cero (3 conv, sin residuales) daba 55.5%; la misma geometría dentro de una ResNet-18 bien construida da 74.8% y gana +0.56 a la euclídea idéntica, en línea con el +0.35 que publican a 200 épocas. La lección, escrita sin maquillaje: los 18 puntos que perdíamos no eran culpa del espacio de Lorentz, sino de una arquitectura pobre. En cuanto la red está a la altura —profundidad, residuales, normalización riemanniana de verdad, MLR—, la geometría hiperbólica entrena sin problemas y aporta una ventaja pequeña pero real, al precio de un cómputo varias veces mayor. El "fracaso" hiperbólico de los capítulos anteriores era, en visión, un fallo de implementación nuestro, no de la geometría.
Cuatro trampas que no dan error pero hunden el resultado
Lo más útil de este episodio es la lista de fallos que no producen ningún NaN ni rompen la geometría —la red entrena y los puntos siguen sobre el hiperboloide— y aun así te cuestan 18 puntos. Por eso es tan fácil concluir en falso que "el hiperbólico no sirve":
- Batch-norm de atajo (
logmap₀ → BN → expmap₀): su capa afín reinfla la escala que acababas de acotar, y linealiza en un solo plano tangente ignorando la curvatura. Lo correcto es la BN riemanniana con centroide de Lorentz, transporte paralelo y varianza de Fréchet. - Sin conexiones residuales: castiga más al hiperbólico, cuyo gradiente ya se desvanece cerca del borde.
- Clasificador de distancia a prototipo (vecino más cercano) en vez de una MLR hiperbólica (distancia con signo a hiperplanos geodésicos).
- Pooling por media aritmética: ni cae sobre la variedad ni es el centroide de Lorentz.
Mejoras y palancas de estabilización
Más allá de corregir lo anterior: (i) curvatura aprendible y por capa; (ii) precisión float64 en las operaciones críticas (arccosh, sqrt, divisiones por normas pequeñas); (iii) la escala interna de Chen por canal y aprendible, no un escalar fijo por capa, para liberar la coordenada radial; y (iv), la más importante, el enfoque híbrido: poner la geometría solo en las últimas capas —donde vive la jerarquía— en lugar de en toda la red. Lo medimos a continuación.
¿Cuánta red necesita ser hiperbólica? (y por qué las barras de error importan)
Barrido sobre la misma ResNet-18 variando dónde vive la geometría: E (nada), EL (solo cabeza Lorentz), EP (solo cabeza Poincaré), L (toda Lorentz). Con una semilla parecía haber una tendencia bonita (más geometría → más precisión, +0.56 para L). Pero con tres semillas y barras de error, esa señal se desvanece:
| CIFAR-100 · ResNet-18 · 50 épocas · 3 semillas | Test Acc@1 |
|---|---|
| E — euclídeo | 74.53 ± 0.26 |
| EL — cabeza Lorentz | 74.28 ± 0.03 |
| EP — cabeza Poincaré | 74.32 ± 0.17 |
| L — toda Lorentz | 74.60 ± 0.15 |
Las cuatro son estadísticamente indistinguibles (banda 74.3–74.6): L gana a E por solo +0.07, muy por debajo de la desviación entre semillas. El "+0.56" de una semilla era un artefacto (una euclídea floja coincidiendo con una Lorentz buena). Honestamente: a este presupuesto, la geometría hiperbólica no compra ventaja medible en visión; el +0.35 que publican (200 épocas) es real pero más pequeño que nuestro ruido de semilla. Lejos de debilitar la tesis, la refuerza con barras de error propias: el hiperbólico aporta donde hay jerarquía en baja dimensión, no en clasificación de imágenes sobre representaciones de alta dimensión.
¿Dónde y por qué gana? Barrido de dimensión
Si empata a dim 512, ¿es que nunca gana, o que esa dimensión es demasiado alta? El superpoder hiperbólico —volumen exponencial— solo paga cuando el espacio escasea. Barriendo embedding_dim aparece un pico claro:
| dim | euclídeo | Lorentz | gap |
|---|---|---|---|
| 2 | 20.90 | 22.15 | +1.25 |
| 8 | 66.40 | 70.19 | +3.79 |
| 32 | 71.55 | 72.60 | +1.05 |
| 128 | 73.21 | 72.53 | −0.68 |
| 512 | 74.53 | 74.60 | +0.07 |

La ventaja hiperbólica es un fenómeno de baja dimensión: pico de +3.79 en dim 8, nula para dim ≥ 128.
Por qué deja de ganar (y el ataque decisivo)
Sondeando los embeddings entrenados: al subir la dimensión el radio se concentra en una cáscara (dispersión CV cae 0.57→0.08) y la métrica de Lorentz colapsa a euclídea (correlación 0.61→0.92). Son el mismo fenómeno: en una cáscara, la distancia hiperbólica se reduce a la angular = euclídea. El pico (dim 8) coincide con métrica aún curva.

¿Ese colapso es un fallo arreglable (A) o lo óptimo (B)? Lo atacamos a dim 128 con un regularizador anti-cáscara que fuerza el radio a no apelotonarse:
| dim 128 | CV radio | corr. euclid | acc |
|---|---|---|---|
| base | 0.083 | 0.924 | 72.53 |
| + learn_k | 0.083 | 0.905 | 72.51 |
| + anti-cáscara | 0.251 | 0.691 | 71.21 |
Veredicto: hipótesis B. El anti-cáscara funcionó (sacó los puntos de la cáscara, CV ×3; descolapsó la métrica, corr 0.92→0.69) y aun así la precisión bajó (72.5→71.2). Forzar la curvatura genuina empeora → el colapso a euclídeo en dim alta no es un bug, es lo que le conviene a la red. La ventaja hiperbólica es un fenómeno de baja dimensión, no un fallo de alta dimensión esperando arreglo.
¿Sirve el hiperbólico con foundation models congelados? (la pregunta práctica)
El estado del arte vive en backbones grandes (DINOv2, CLIP…). ¿Puede uno congelado ganar proyectando a una cabeza hiperbólica de baja dimensión? Ojo a la distinción: una cosa es la dimensión del backbone (384 en DINOv2) y otra la del espacio hiperbólico de salida (que eliges tú). Lo medimos: misma feature congelada, cabeza euclídea vs Lorentz.
| dim cabeza | acc E | acc L | Δ |
|---|---|---|---|
| 8 | 72.72 | 61.51 | −11.2 |
| 16 | 80.63 | 66.81 | −13.8 |
| 32 | 83.62 | 67.30 | −16.3 |
| 64 | 83.89 | 67.03 | −16.9 |

NO, y medido: la cabeza hiperbólica pierde 11–17 puntos en toda dimensión útil, comete errores más severos, y se satura en ~67% mientras la euclídea sube a 84% (ni siquiera aprovecha la capacidad de las features). No contradice el +3.79 del HCNN: entrenado de cero, el cuello hiperbólico moldea features jerárquicas; pero DINOv2 da features fijas e isótropas (optimizadas para separación lineal), y la cabeza solo las proyecta — meterlas en espacio curvo las distorsiona. Conclusión práctica: con foundation models grandes y congelados el hiperbólico no compra precisión; su valor es la estructura (jerarquía, entailment, radio=incertidumbre, seguridad), no el top-1 — que es justo para lo que lo usan MERU, los CLIP hiperbólicos y los VLMs de seguridad.
Dónde SÍ supera al euclídeo: compresión y retrieval (memoria hiperbólica)
Tras descartar la accuracy de clasificación por todas las vías, buscamos el eje donde la ventaja teórica del hiperbólico (embeber jerarquía en pocas dimensiones) sea real. Lo encontramos, y es doble.
1) Frontera de compresión. La curva accuracy–dimensión de Lorentz va desplazada a la izquierda: misma precisión con menos dims. A dim 4, +8.1 puntos directos; factor de compresión ~3× (Lorentz dim 8 ≈ euclídeo dim 24).

2) Retrieval (memoria). Recuperación por vecino más cercano: el modelo de Lorentz gana a toda dimensión, y la ventaja NO se desvanece en alta dim (al revés que la clasificación), porque el retrieval depende de la métrica cruda. Verificado con 3 semillas (gaps ≫ desviación):
| dim | P@10 fina E | P@10 fina L | Δ fina | Δ super |
|---|---|---|---|---|
| 8 | 54.6±0.6 | 56.8±0.1 | +2.15 | +0.98 |
| 32 | 56.1±0.1 | 59.7±0.6 | +3.55 | +1.90 |

Veredicto positivo de cierre: el espacio hiperbólico no bate el accuracy pico del SOTA en visión, pero sí lo supera de forma robusta en representación compacta (~3× menos dimensiones a igual accuracy) y en calidad de retrieval (mejor recuperación, sobre todo jerárquica, a toda dimensión). El valor del hiperbólico es la estructura métrica en espacio compacto — memoria y recuperación —, no la clasificación plana. (La atención hiperbólica existe —Gulcehre 2019— pero hereda el mismo veredicto que la clasificación: terreno de alta dimensión isótropa.)
¿La hiperbolicidad de las representaciones es real o concentración de medida?
Pregunta abierta de cierre, con consecuencias para todo el deep learning geométrico: la aparente hiperbolicidad de los foundation models, ¿es estructura genuina o artefacto de la dimensión?
H1 — La δ-hiperbolicidad está confundida por la dimensión. La δ de Gromov de ruido gaussiano puro cae al subir la dimensión (0.094 en d=2 → 0.0066 en d=2048): en alta dim, datos sin estructura ya parecen tipo árbol. Es concentración de medida — las distancias (también las hiperbólicas) concentran a ~1/√d; la curvatura negativa no protege. (Referencias: árbol perfecto δ=0, ruido plano baja-dim δ≈0.082.)
H2 — Con el null correcto (misma covarianza y dim), hay hiperbolicidad genuina, pequeña y universal. Comparando cada modelo contra un gaussiano de su misma covarianza (que descuenta la estructura lineal), 4 semillas:
| Backbone | dim | δ modelo | δ null cov. | gap genuino |
|---|---|---|---|---|
| DINOv2 | 384 | 0.0177 | 0.0229 | +0.0052 |
| CLIP | 512 | 0.0255 | 0.0306 | +0.0051 |
| ResNet50 | 2048 | 0.0234 | 0.0285 | +0.0052 |
| ViT-sup | 768 | 0.0236 | 0.0281 | +0.0045 |
| ConvNeXt | 1024 | 0.0203 | 0.0267 | +0.0064 |

El gap es ~10-25× su desviación (real) y consistente en las 5 arquitecturas pese a dimensiones 384-2048 — sabor platónico. Aviso clave: contra un null isótropo los modelos parecen más planos; solo el null de covarianza revela la jerarquía genuina. Conclusión: medir curvatura de representaciones de alta dim sin null de covarianza engaña; hecho bien, los foundation models comparten una hiperbolicidad genuina pequeña pero universal. Y explica todo el proyecto: gran parte de la "estructura hiperbólica" de las features de alta dim es espejismo dimensional — la genuina es minúscula, y por eso el hiperbólico aporta poco en visión.